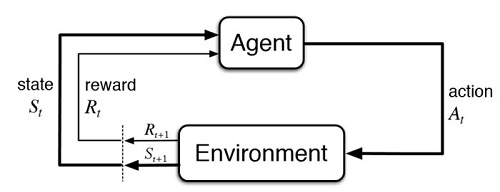
強化式學習之11~訓練與實行 Leave a Comment / Blog7 / By 楊慶忠 3-11:訓練與實行我們先前每個AI遊戲的練習,都是讓程式跑了很多個小時之後,才能看到訓練的成效。這在訓練模型階段是不可避免的,訓練人工智慧的過程,本就是最消耗運算資源的。 一旦模型訓練到合乎我們的預期後,就可以把訓練結果直接拿來應用,不需要再每次都花那麼多時間了。如果是神經網路,就是把得到的權重係數儲存再載入,而我們現在的強化式學習,則是把多次修正後的Q-table存成 ***.npy檔案,然後在另一個相近的程式中載入再執行。 這個AI遊戲,我們將畫面像素,由400×400增加至600×600,但訓練的時間反而減少了,這是因為我們讓裡面的人物每走一步要跨過20個像素,所以狀態數會減少。即便如此,所儲存的Q-table,仍佔了超過1G的容量,因此在載入檔案階段,有花了一些時間。 在人工智慧模型建立過程中,就監督式訓練而言,最花時間的,其實是在準備資料和整理資料階段。但對強化式學習而言,這個階段的時間倒是可以節省下來,因為它所修正的資料,是由它自己計算而得的。