強化式學習之14~很重要又難理解的Policy Gradient
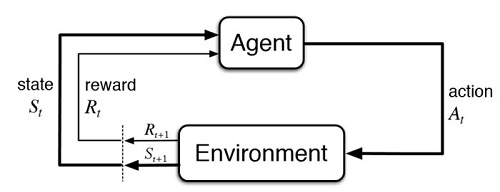
3-14:很重要又難理解的Policy Gradient 使用神經網路在做分類訓練時,輸出層的節點值,必須先轉換成機率分佈,再和標記值(標準答案)相比對,以計算彼時參數應該被修正的程度。 一旦模型訓練完成,進入到推論(inference)階段,就不會再有標準答案了,這時候,要直接從機率分佈選取一個最大的,做為判斷的種類。如下圖中的x3節點將會被選取,因為它的機率值是0.4,大於其他的節點值。 圖3-14-1. 神經網路輸出層的預測值是機率分佈。 在強化學習當中,從某個狀態來選擇某種動作,早期的做法相類似,也是去選取動作值(action value)最大的那一個,但這樣的處理,衍生出了一些問題。 它會讓決策僵化,只想遷就眼前最大的獎勵,而不願去多方嘗試最佳路徑。為改善此缺失,實作上通常還會再引入隨機變量epsilon,來增加探索性,這就是為什麼我們問ChatGPT同一個問題,它常常會給出不同答案的原因。 強化式學習發展至今日,結合了神經網路之後,最新的做法,也是在輸出層節點形成機率分佈,但動作的選取,不再獨厚機率值最高的那一個了。 圖3-14-2. 強化式學習神經網路。 上圖左邊是輸入神經網路的狀態(state),右邊是經過神經網路計算後,得到的動作機率分佈。在選擇動作時,是採用隨機(stochastic)的方式,機率大的當然被選取的機會就高,但機率小的,仍然有較低的機會被選取到。 看得出來,這種選取方式,就是將隨機變量epsilon,直接放進決策過程中了。它不但讓程式語法變得更簡潔,背後的數學思考也更加深邃。 我們將這種學理應用在迷宮遊戲中,和DQN(Deep Q-Network)相比較,發現它學習的進步幅度非常明顯,因為它一邊學一邊修正,十分有效率。 圖3-14-3. 策略梯度的演算法,讓AI學習更加有效率。 Policy Gradient,策略梯度,是要逐步修正神經網路裡面的參數值,讓輸出的動作機率分佈,有助於提升每回合時間序列的報酬值(return)。 這是相當不好理解的關鍵,它不像監督式訓練,每次都附帶有標準答案來比對修正。事實上,它每次的「標準答案」,都是來自神經網路中途參數的預測,換句話說,它自己提供數據來訓練自己,這是強化式學習很特殊的地方。
強化式學習之14~很重要又難理解的Policy Gradient Read More »