自然語言處理之3~ChatGPT做程式設計
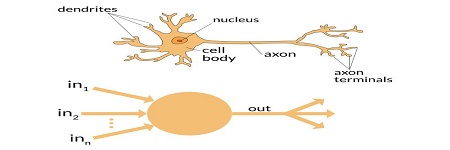
2-3:ChatGPT做程式設計 使用ChatGPT整理資料或創作文字,適當的提問(prompt)是很重要的。好的提問可以做出有效的條件限制,讓它回答的內容,合理地限縮在你所需要的範圍內。 但一般人的日常對話,或者在社群平台輸入的文字,通常都比較隨興,不會刻意去講究文法和邏輯。因此在善用此項工具前,是需要花點時間學習,才能理解提問的重要性。 ChatGPT裡面,有非常強大的程式設計功能,因為它本身的神經網路機制,就是複雜又精巧的演算法。撰寫普通的程式碼,對它來講,僅是牛刀小試,但是提詞的技巧在此也益形重要。 圖2-3-1. 使用ChatGPT,來設計一個九九乘法表的程式碼。 上面的九九乘法表Python程式碼,是由ChatGPT所提供答覆,我們在提問階段,有給予一些限制,完整的提詞內容如下:”請設計一個Python程式, 可以輸出由左而右水平排列的九九乘法表. 其中, 乘數和被乘數需兩兩交換位置, 乘積的個位數需對齊. 請不要使用function, 只使用最常見之基本語法及最少之行數.”。 我們用prompt做出層層限制,其實是在用文字來代替程式碼的指令。這樣的方式,多嘗試幾次就比較能夠掌握了。複製上面的程式,再拿到Spyder軟體上執行後,得到下列的結果,看的出來,它的確有按照我們的要求在建立其邏輯。 圖2-3-2. 執行程式得到的九九乘法表,其輸出的的格式,有刻意用prompt去要求。
自然語言處理之3~ChatGPT做程式設計 Read More »