自然語言處理之1~編碼器與解碼器
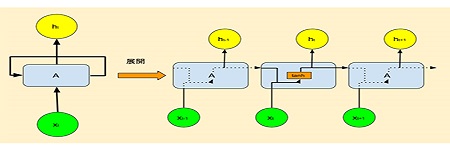
2-1:編碼器與解碼器 在RNN早期階段,它常被使用在翻譯上,在某個時序輸入一個詞,就可以在同一時序得到相對應的輸出,這跟早期翻譯的模式很接近。 尤其是用英文來翻譯法文或西班牙文,這種一進一出的架構,對語系相近的文字很有利。但如果是翻譯中文和英文,問題就比較多了。 中文句子不像英文,可以利用句子當中的空格,把單字分開為各個詞彙。中文句子每個字都是並排靠攏在一起,例如像「我打遍天下無敵手」,其實包括了「我」、「打遍天下」、「無敵手」這三個詞彙。所以中翻英輸出和輸入長度常常是不一樣的。 類似這種情況,在文章摘要和文字創作都會出現。所以,序列對序列(Sequence to Sequence,Seq2Seq),這種架構就自然而然的被推出來了。這種架構包含一個編碼器和一個解碼器,容許輸入和輸出長度不同,如下圖所示。 圖2-1-1. 編碼器與解碼器構造。 上圖上是在訓練階段,解碼器輸出必須和標記值比對,以回饋修正模型權重值;上圖下則是在預測階段,用「文字接龍」的方式,逐一輸出整個句子或段落。 目前的文字生成,除了摘要和創作,還包括製表、繪圖甚至寫程式,但設法提升傳統翻譯精準度,在自然語言模型發展過程中,實在有很基本的貢獻。 一般人學習英文,常常感覺英文單字背了又忘、忘了又背,原因在於盎格魯、薩克遜是日耳曼人分支,且法國諾曼第威廉公爵,也曾在11世紀跨海統治過英倫,把法文詞彙帶進英文當中,英文字彙因而是德語加上法語的總和,所以英文難學是必然的。但在AI鋪天蓋地席捲而來之際,把英語學好,總是會比別人多佔一些優勢。 圖2-1-2. 威廉公爵的領地諾曼地(Normandy),是二戰盟軍反攻的主戰場。