強化式學習之10~藍波之AI版本
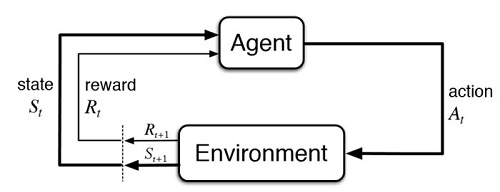
3-10:藍波之AI版本 先前第8單元的AI版本無人駕駛遊戲,如果把它的物件設計成各種實際個體,透過Pygame模組的2D美工和程式技巧,很快的就可以將它轉成AI版本的藍波遊戲,這個遊戲主角是源自於古早的電影「第一滴血」。 「第一滴血」中的藍波(Rambo),可以在槍林彈雨中深入虎穴,痛擊歹徒搶救人質,簡直神通廣大無所不能。演員出身的美國前總統雷根曾戲稱,萬一再有類似越戰人質的事件,一定要派藍波去搶救才行。 https://mobile-learning-testing.com/wp-content/uploads/2025/04/reinpon5.mp4 這個AI遊戲,只不過將畫面像素,由300×300增加至400×400,但訓練的時間,竟長達了12個小時。其原因在於,雖然狀態項目一樣,但每個項目的元素數目增加了不少,如果再形成多維陣列,則其狀態的排列組合就多了好幾倍。 即便如此,這和現實工作場景的狀態數相比較起來,仍然是小巫見大巫。目前的Q-learning演算法,是使用類似查表的方式修正其Q值,如果狀態數大幅增加之後,就有可能會使用到DQN的技術了。 DQN,Deep Q Network,它的Q值修正,是在原有的動作值函數基礎之上,再加入了深度神經網路的技巧,也因此消耗更多的計算資源。照理,是可以使用Google Colab來加速其神經網路的計算,但Colab並不支援Pygame的顯示視窗,所以到目前為止,我們的AI遊戲都還是使用未安裝GPU的個人電腦,來進行簡單的Q-table計算。