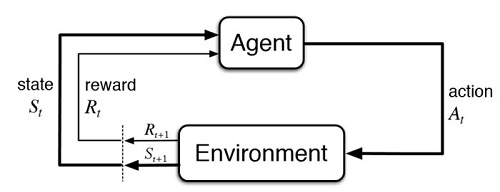
強化式學習之7~AI版本動態遊戲初探 Leave a Comment / Blog7 / By 楊慶忠 3-7:AI版本動態遊戲初探 我們在前面的單元,曾使用Q-learning來訓練迷宮遊戲的主角(agent),讓他可以摸索出最佳路徑,以找出固定位置的寶藏目標物,並避免誤闖大魔王所在地。 這個單元,我們嘗試讓目標物變得可以移動,看看是否仍然有機會成功訓練agent,讓他也可以找到移動中的目標。 我們直接引用前面設計好的球和磚塊,把磚塊當作目標物而把球當作agent,先讓磚塊循著一定的軌跡移動,再觀察經過一段時間訓練後,球是否有機會決定出最短路徑來擊中磚塊。 經由上面的訓練,我們可以看出來,只要訓練回合數夠多,在簡單的架構下,主角依舊很有機會找到移動式的寶藏。但如果魔王也是移動式的,這樣的演算邏輯是否還可以擴充套用,就必須再加上新的元件來驗證。一般遊戲中的寶物和敵人,都有可能隨情境變動其位置,甚至不少遊戲的空間還是以3D的方式來呈現。但若要將AI訓練的部份再加進遊戲中,則必須一步一步來測試策略是否仍然可行。因為除了演算法要行得通之外,運算資源的使用,也會隨著狀態(state)、動作(action)的增加,快速提升其需求量。