Line這個即時通訊軟體,在台灣有超高的使用率,幾乎接近百分之百。除了圖文影音的通訊功能外,它還是個越來越受重視的行銷利器。
Google和Facebook的廣告對象比較聚焦,可以針對目標小眾進行精準投放。Line在這方面的功能不遑多讓,甚至還猶有過之。
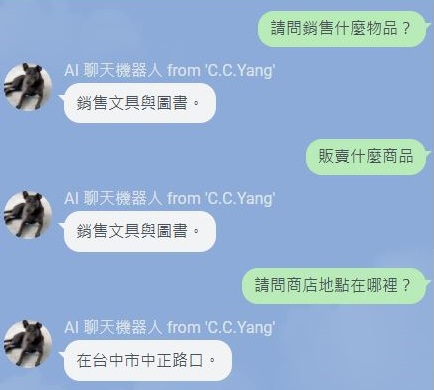
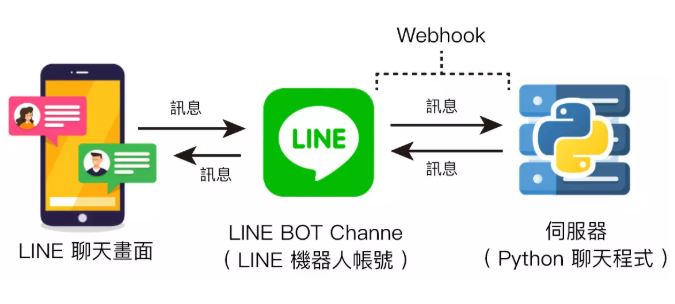
例如,Line Bot已經整合AI到群組裡面去了,讓它開拓市場的方式更加多元。Bot是Robot(機器人)的意思,在此尤指聊天機器人,我們可以訓練它來做簡單的客服工作。
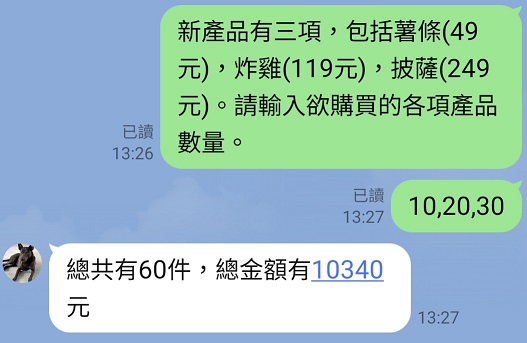
下圖可以看得出來,經過少許訓練之後,即使問的方式有些差異,LineBot還是能揣摩出問話者的意圖,因為它在預訓練階段,語言模型的結構已相當完整了。