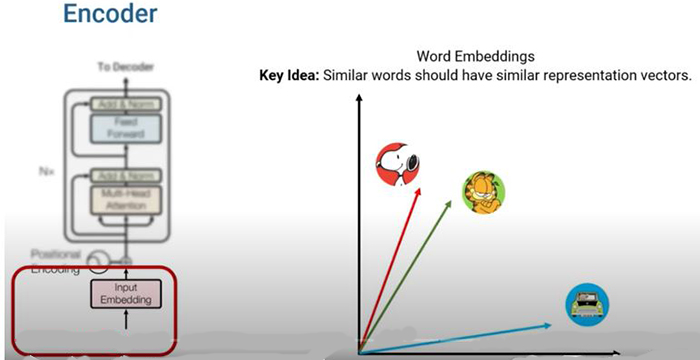
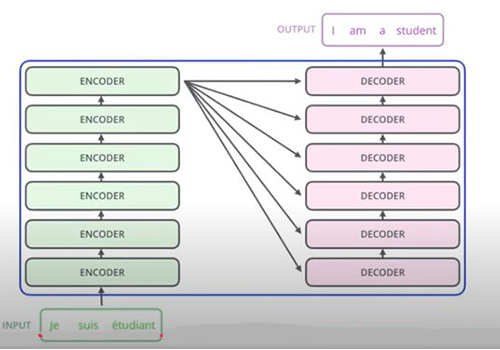
自然語言處理之6~ChatGPT的基礎Transformer Leave a Comment / Blog6 / By 楊慶忠 2-6:ChatGPT的基礎Transformer目前熱門的生成式AI技術,包括ChatGPT和Gemini及Llama等,它們都是建立在Transformer演算法的基礎之上。開發者會使用「Transformer」這個名稱,也許是因為它使用到多頭多層的架構,宛如組合積木般層層堆疊而上,有利於擴充其權重數至百億個或更多。 圖2-6-1. Transformer也是相當受歡迎的電影”變形金剛”。 而Transformer的核心,則在注意力(Attention)的運算。注意力機制源自人類的視覺行為,好比我們在看下面圖片時,我們會重點式的先看嬰兒臉部表情,以及標題列和內文第一行,再顧及嬰兒紙尿布的說明,而不會鉅細靡遺的把整張圖片都看完。 注意力機制早期是應用在電腦視覺上面,但真正受到眾人矚目的,是使用在自然語言處理之後的卓越表現。例如我們現在英翻中一個句子,”I am walking to the river bank.”,當翻譯到”我正走向河X”的時候,這個X,如果有注意到river和bank的關係,或者有參照到已經翻譯出來的中文部份,則接在”河”後面的字詞,”岸邊”要比”銀行”好多了。 我們對模型輸入文字時,第一步,是先將英文單字或者中文詞彙,利用詞嵌入(Word Embedding)技術,將其轉換成向量的型態,稱之為「詞向量」(Word Vector)。向量裡面純量元素的個數,名之為長度或「維度」,有時維度可達512或更多。一個句子裡面有好幾個單字,一個單字會使用到一個向量,把這幾個向量堆在一起就成了矩陣。 詞向量裡面某個維度數字的大小,可視為這個單字所具某種屬性的強弱。例如下圖中,4個單字的向量維度都是7,第1個維度living being表示其生物屬性,cat、kitten、dog都有一定大小,但houses就是負值了;第2個feline表示其貓科屬性,cat、kitten都很高,dog和houses都是負數了;而第7個維度plural表其名詞複數形屬性,最高的就是字尾有加s的houses。 各個單字,用詞向量表示後,彼此之間的相關程度,可以從這些向量相靠近的程度看得出來,如下圖的貓和狗的關係就勝過和汽車的關係。向量靠得越近,夾角越小,其cosine值越大。我們知道兩個向量的內積(dot product)值,是和cosine值呈正比,所以就可以用向量內積值來表示彼此相關的程度。 輸入句子所形成的矩陣,要進行自我注意力(Self Attention)之前,先要把維度減少,所使用的轉換矩陣,就是即將要訓練的權重矩陣。這個部份,都是把輸入矩陣X轉換成三個矩陣Q、K、V,這三個新矩陣,意義很相近,都是原始矩陣X降維的結果。所以可以進行Q、K之間的內積運算,將其得到的加權值,乘上V矩陣,就是有考慮到詞向量彼此關係的新矩陣Z了。 圖2-6-2. Q和K矩陣相乘時,K矩陣有先做了一個轉置(Transpose)的動作,將列轉成行,才能進行兩個矩陣的內積運算。註:中國大陸和台灣對於列跟行的定義,剛好相反,但如果使用row和column就沒有問題了。 輸入矩陣X所轉換的三個矩陣,Q、K、V,可以三個一組形成好幾組,這樣一來,要訓練的權重矩陣就可多出好幾倍,這就是多頭注意力(Multi-head Attention)的概念。甚至,還可以將輸出當作另一層的輸入,重複類似的計算步驟,使用多層訓練來得到更多的權重矩陣。 整個完整的架構,就如下圖所示。在左邊的編碼器(Encoder)和右邊的解碼器(Decoder)當中,各有一次的自我注意力運算,但在解碼器中,又多了一次一般注意力(cross attention)運算,它是把自己的Q矩陣,和編碼器的K矩陣做內積再乘上編碼器的V矩陣。這樣的操作是可以理解的,例如在做翻譯時,譯文必須參考原文,也要參考已經翻譯出來的部分。 我們把上面的架構圖,其執行注意力機制的過程,用下面一個簡單的動畫來綜合說明。