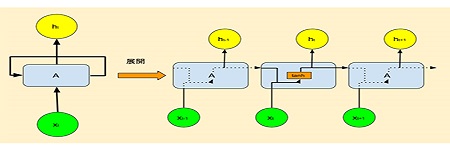
在RNN早期階段,它常被使用在翻譯上,在某個時序輸入一個詞,就可以在同一時序得到相對應的輸出,這跟早期翻譯的模式很接近。
尤其是用英文來翻譯法文或西班牙文,這種一進一出的架構,對語系相近的文字很有利。但如果是翻譯中文和英文,問題就比較多了。
中文句子不像英文,可以利用句子當中的空格,把單字分開為各個詞彙。中文句子每個字都是並排靠攏在一起,例如像「我打遍天下無敵手」,其實包括了「我」、「打遍天下」、「無敵手」這三個詞彙。所以中翻英輸出和輸入長度常常是不一樣的。
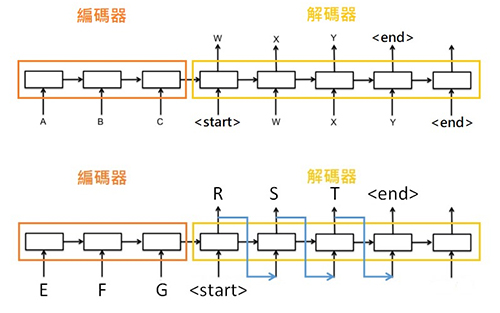
類似這種情況,在文章摘要和文字創作都會出現。所以,序列對序列(Sequence to Sequence,Seq2Seq),這種架構就自然而然的被推出來了。這種架構包含一個編碼器和一個解碼器,容許輸入和輸出長度不同,如下圖所示。