It’s fascinating how Policy Gradient essentially uses the network’s own predictions as the “standard answer” for training – a really unique aspect of reinforcement learning. I found some helpful visualizations of similar concepts while exploring https://tinyfun.io/game/formula-traffic-racer.
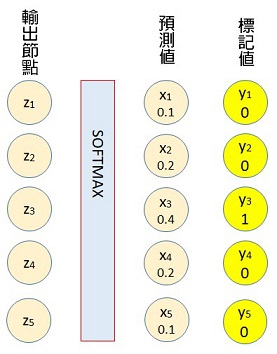




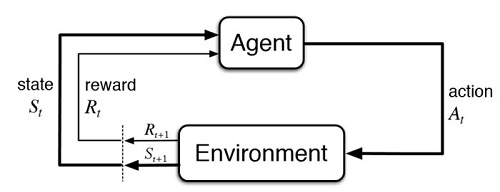
It’s fascinating how Policy Gradient essentially uses the network’s own predictions as the “standard answer” for training – a really unique aspect of reinforcement learning. I found some helpful visualizations of similar concepts while exploring https://tinyfun.io/game/formula-traffic-racer.