早先提到的CNN神經網路中,其遮罩的係數(也就是權重),一開始是用隨機的方式來指定,在多次的訓練之後,會利用越來越小的誤差,逐步修正到比較合適的權重值。中間的步驟,也有用拋棄層(Dropout Layer)來做隨機處理的。
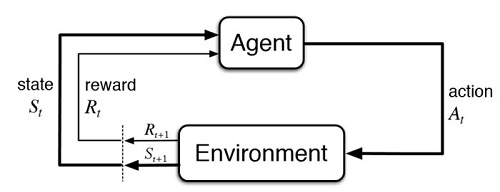
而增強式學習的隨機選擇考量,則是因為訓練初期獲得的資訊量有限,所以讓模型勇於嘗試各種可能性,在歷經了各種情況且反覆摸索之後,計算出最大報酬值以找出最好的策略。
前者隨機的部份是在訓練開始就全部完成,後者是在訓練過程逐次降低其比重。兩者相似的地方,就是隨機計算的處理都很快速,只不過一個是在神經層,另一個在時間序列當中。
蒙地卡羅模擬(Monte Carlo Simulation),是著名的隨機運算技術,它利用亂數產生器得到大量隨機數據,分析其統計分佈,進而引用來估計實際問題的答案,常被應用在增強式學習當中。