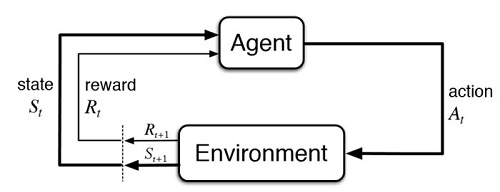
監督式學習,好像是學生在準備社會科考試一樣,唸的題目越多,背的標準答案越多,答題的準度和分數就會越高。但是要從90分考到95分,究竟要再多記憶多少內容,沒有人能提出精準的數據評估,甚至多背些考題是否一定就會提高分數,也很難講。
而且,除了記憶事物之外,舉一反三、觸類旁通的能力也很重要啊!它讓我們可以從有限的記憶中,摸索推理出不曾背誦過的資訊,這也許是人類智慧中更重要的部份。
例如有個題目問,“美國第一大都市在哪裡?”,我們很快可以回答是“紐約市”。如果再問“紐約在荷蘭人佔領期間的名稱是甚麼?”,或者“新阿姆斯特丹的北城牆,為現今金融中心的甚麼街?”,這些加以思考推理或許就可得到的答案,監督式學習必須輸入更多的資料來訓練,否則無法回答。
所以有好事者比喻,一味地只知道使用監督式學習,就像是古代巴比倫人建好巴別塔,自認為已經可以通達天際了,實際上還差了十萬八千里。