增強式學習這幾年來廣受各方矚目,主要的原因,當然是它成功地被引用在ChatGPT當中。但除了大型語言模型,增強式學習還有很多重要的應用,例如像無人載具、機器人的路徑規劃,以及數位電路、核融合及渦輪引擎的效率最佳化設計等。
增強式學習的基本概念,在於透過多次訓練逐步形成最佳策略,以找出最大報酬的最適路徑。迷宮遊戲,是最常被拿來舉例說明的範本。
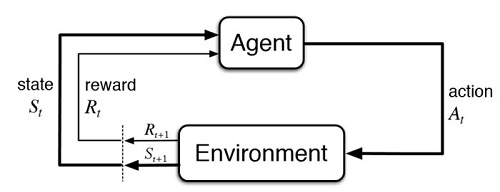
圖3-1-1上圖之中,橘色球形代表遊戲的主角(agent),整個6×6迷宮就是環境(environment),其中任何一個格子的x,y座標就是狀態(state),橘球要上下左右朝哪一方向移動,就是行動(action)。
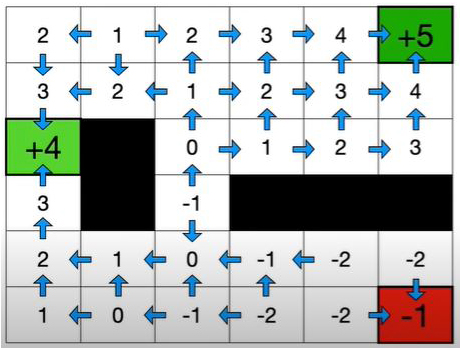
走到相鄰任何格子的獎勵(reward)應為 -1,但有兩個格子獎勵為4和5,其中並有黑色的障礙禁止區。想要成功走完迷宮的基本邏輯思考,就是以最少的步數走到獎勵為5的格子,來獲得最大的“累積獎勵”(稱為“報酬”,return)。
圖3-1-1下圖之中,是在說明,經過多個回合(episode)的訓練,系統會慢慢計算出每個格子的價值(state value),agent在決定要朝哪個方向移動下一步時,就會傾向鄰近價值最高的格子,並更新目前所在格子的價值,這就是所謂的策略(policy)。