ChatGPT這種語言模型,是屬於監督式學習,例如訓練英翻中的時候,輸入一個英文句子“I have been expecting you.”,一定要同時輸入它的中文翻譯“我恭候您多時了”,用以計算其損失函數,做為回饋修正模型權重之用。模型訓練完成可以回答提問者的問題了,就是到了模型預測的階段。
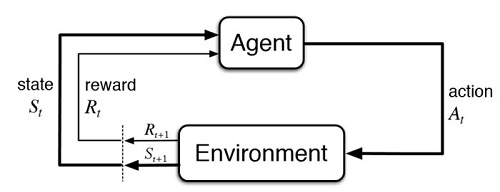
但我們在不同時間點,問ChatGPT同一個問題,常常會得到有所差異的答覆。這是因為,模型一般是利用(exploit)學習經驗回答問題,但有時會探索(explore)隨機答案,目的是想增加回答內容的多樣性。
如此一來,在預測階段所提的問題,如果不同的答覆內容給予不同的評分,就可以再放進模型裡面,當作另一筆訓練的資料和標記值。這樣的學習訓練方式,讓ChatGPT在往後的答覆更加合理,並且文字益形通順。
例如,“You should have studied harder.”,如果翻譯成“你原本應該更用功讀書”給予5分,如果翻成“你應該更用功讀書”給予3分,如果翻成“你應該用功讀書”給予1分。這樣的獎懲方式是「強化式學習」的基本概念,搭配上既有的監督式學習,是OpenAI公司迎頭趕上Google的重要關鍵。