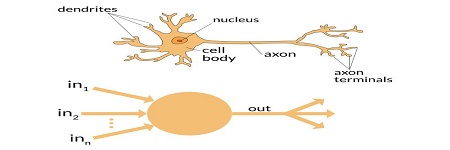
前面提到的影像辨識,僅能從一張圖片當中,判斷其內容是屬於哪一類物體。如果換個角度來看,十幾萬個像素灰階值,經過模型計算輸出後,只能得到一個編號值,這是相當不經濟的。
至少,模型應該可以從圖片中辨識多於一種物體,而且各種物體的位置大小也都可以判讀出來,這樣的神經網路,才能提供足夠多的訊息給使用者。
影像分割的目的,就是要簡化影像的表示形式,使其更容易被理解和分析。這個領域的發展,近年來引進人工智慧的活力後,重點在於將圖片中的不同物體各自所包含的範圍,標記出一致性的灰階值。這種方式叫做語意分割(Semantic segmentation),意即對圖片內容涵意的理解。