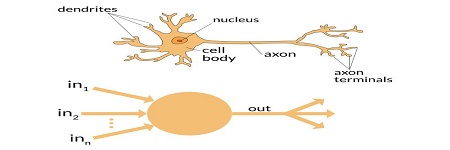
前面提到的機器學習,在使用波士頓房價資料集做迴歸分析時,其特徵(變數)有13個,相對應的權重(參數)也有13個。但到了深度學習階段,變數參數達數萬或數百萬以上是很平常的。
比如在訓練影像辨識模型時,輸入的影像上每個像素灰階值,都可被當作是一個特徵值;將它每兩相鄰神經層的節點數相乘再做加總,就決定了其所有參數的數目。
當然這樣的計算是比較傳統,並不完全適用在所有的情況當中,因為影像中任一像素的灰階值,都會與相鄰像素有關。所以在實務上,卷積神經網路(CNN)是最常用的演算法,它的參數是存在於處理卷積運算的遮罩當中。
下面的圖形,是來自於手寫阿拉伯數字資料集,從這數萬張圖片的其中10張,可以一葉知秋,為何自大航海時代以來,辨識潦草的阿拉伯數字,會一直困擾著與數字為伍的行政人員。